Building a Machine Learning Stock Trading Bot

Introduction
My favorite class in grad school was Machine Learning for Trading combining two of my favorite hobbies - coding and stock trading. The class emphasized to not use what we learned in class in the real world, but it was hard to resist applying the knowledge I learned to potentially make me money (or to lose everything, but whats life without risk).
I primarily used this bot to trade covered calls since it can be a profitable strategy. I started using this strategy manually around the Gamestop and AMC phenomenon and decided I wanted to automate the process. I'll cover the tools to create a stock trading bot designed specifically for trading, the techniques used, the API that facilitated the trades, and share some insights with graphs and code snippets.
This can be used for any style of trading, but I made mine specifically for covered calls.
Disclaimer
I am not a financial advisor and I made this purely for enjoyment and to see if I could apply my knowledge. I am not trying to beat the market or time it perfectly, I made this to manage my covered calls specifically and to make alerts when my calls sell, and based on the history and news, to alert me if it is ideally a good time to buy the stock.
Understanding Options
Before diving deeper, let's clarify some key terms related to trading:
- Call Option: A financial contract that gives the buyer the right, but not the obligation, to buy a stock at a specified price within a specified period of time.
- Put Option: A financial contract that gives the buyer the right, but not the obligation, to sell a stock at a specified price within a specified period of time.
Covered calls involve selling call options on the same asset. This strategy generates income through the premium received from selling the call options, while also having the potential for capital gains if the stock price appreciates.
Covered vs. Naked Options
- Covered Call: This involves owning the underlying stock while writing (selling) a call option. This strategy is considered less risky because you own the stock and can deliver it if the option is exercised.
- Naked Call: Selling a call option without owning the underlying stock. This is risky because if the stock price rises significantly, you could face unlimited losses since you'd have to buy the stock at a high price to fulfill the option.
I choose to sell only covered calls to manage risk. Since I own the underlying stock, I can avoid the potentially unlimited losses associated with naked calls.
Why Use Q-Learning?
Q-Learning is a type of reinforcement learning algorithm that is well-suited for sequential decision-making problems (such as trading) where the goal is to learn the optimal strategy over time. Here are some reasons why Q-Learning is a good choice for building a stock trading bot:
- Adaptability: Q-Learning can adapt to new data and changing market conditions. It continuously learns and updates its strategy based on the latest information.
- Model-Free: Unlike other methods that require a model of the environment, Q-Learning is model-free and learns the optimal policy directly from interactions with the environment.
- Simplicity: Q-Learning is relatively simple to implement and understand compared to other complex reinforcement learning algorithms.
- Scalability: It can be scaled to handle large state and action spaces, making it suitable for complex trading environments.
However, Q-learning takes a large amount of data and time to train to converge to an optimal strategy.
Alternative Models to Consider
I learned this method in class and was the most comfortable with it which is why I decided to use it in my example. However, it is not the only algorithm suitable for stock trading. Here are some alternative models to consider:
- Policy Gradient Methods: These methods, such as REINFORCE and Actor-Critic algorithms, directly optimize the policy instead of the value function. They can be more effective in environments with continuous action spaces.
- SARSA (State-Action-Reward-State-Action): Similar to Q-Learning but updates the Q-value based on the action actually taken by the policy, providing a more on-policy learning approach.
- Long Short-Term Memory (LSTM) Networks: A type of recurrent neural network (RNN) that can capture temporal dependencies in time-series data, making it useful for predicting stock prices and making trading decisions.\
- Genetic Algorithms: These evolutionary algorithms can optimize trading strategies by simulating the process of natural selection. They are useful for finding good solutions in large search spaces.
- Support Vector Machines (SVM): A supervised learning algorithm that can be used for classification and regression tasks. It can be applied to predict stock price movements and make trading decisions.
The Plan
- Data Collection: Gather historical stock and options data.
- Feature Engineering: Prepare and preprocess the data.
- Model Training: Use ML models to predict stock prices and volatility.
- Strategy Implementation: Implement the covered call strategy using the predictions.
- Execution: Use an API to execute trades automatically.
- Evaluation: Assess the performance of the strategy.
Tools and Technologies
- Programming Languages: Python
- Machine Learning Libraries: Scikit-learn, TensorFlow
- Data Handling: Pandas, NumPy
- API for Trading: Alpaca, a commission-free trading API
- Data Visualization: Matplotlib, Seaborn
Step-by-Step Process
- Data Collection
The first step is to gather historical stock data and options data, which serves as the foundation for training your model. The data will allow the Q-Learner to understand the environment it will operate in, including price movements and volatility.
We can use an API like Alpaca to fetch historical stock prices and additional sources for options data.
stock_datacontains daily historical prices for an example stock like Apple('AAPL'). This is critical for making predictions and understanding market trends.- Options data, when available, provides insights into market sentiment and potential price movements.
import alpaca_trade_api as tradeapi
api = tradeapi.REST('APCA-API-KEY-ID', 'APCA-API-SECRET-KEY', base_url='https://paper-api.alpaca.markets')
# Fetch historical stock data
stock_data = api.get_barset('AAPL', 'day', limit=1000).df
# Fetch options data (use a third-party service if Alpaca doesn't provide options data)
options_data = fetch_options_data('AAPL')- Preprocessing Data
Raw data often needs to be cleaned and structured before it can be fed into the Q-Learner. This includes normalizing prices and creating features that help the model make decisions.
We can normalize the data and create technical indicators (e.g., Simple Moving Average, Bollinger Bands).
- Normalization is scaling prices to help the model learn without being biased by the magnitude of raw prices.
- SMA & Bollinger Bands indicators help the model identify trends and volatility, informing buying/selling decisions.
import pandas as pd
# Normalize stock prices
stock_data['normalized_close'] = stock_data['close'] / stock_data['close'].iloc[0]
# Create state representation (e.g., using moving averages, Bollinger Bands, etc.)
stock_data['SMA'] = stock_data['normalized_close'].rolling(window=20).mean()
stock_data['SMA_ratio'] = stock_data['normalized_close'] / stock_data['SMA']- Implementing Q-Learning
The Q-Learner is the core of your trading bot. It uses a Q-table to learn the best actions (buy, sell, hold) based on the state of the market.
We can define the Q-Learner class with essential parameters like the learning rate (alpha), discount factor (gamma), and exploration rate (rar).
- Learning Rate (alpha) controls how much new information overrides old information. A higher alpha makes the model learn faster but might make it unstable.
- Discount Factor (gamma) balances immediate and future rewards. A higher gamma makes the model consider long-term gains.
- Exploration Rate (rar) lets the the model explore more; as training progresses, it exploits learned knowledge by choosing the best-known action.
import numpy as np
import random
class QLearner:
def __init__(self, num_states, num_actions, alpha, gamma, epsilon, decay_rate):
self.num_states = num_states
self.num_actions = num_actions
self.alpha = alpha # Learning rate
self.gamma = gamma # Discount factor
self.epsilon = epsilon # Exploration rate
self.decay_rate = decay_rate # Exploration decay rate
self.Q = np.zeros((num_states, num_actions))
def choose_action(self, state):
if random.uniform(0, 1) < self.epsilon:
return random.randint(0, self.num_actions - 1)
else:
return np.argmax(self.Q[state, :])
def update_Q(self, state, action, reward, next_state):
best_next_action = np.argmax(self.Q[next_state, :])
td_target = reward + self.gamma * self.Q[next_state, best_next_action]
self.Q[state, action] += self.alpha * (td_target - self.Q[state, action])
self.epsilon *= self.decay_rate
# Initialize Q-Learner
num_states = 100 # Example value, should be determined based on your state representation
num_actions = 3 # Example actions: 0 = hold, 1 = buy, 2 = sell
learner = QLearner(num_states, num_actions, alpha=0.1, gamma=0.9, epsilon=0.2, decay_rate=0.99)- Strategy Implementation
The Q-Learner needs to experience different states and actions to learn the optimal strategy. Training involves simulating trades and updating the Q-table based on the rewards received.
We can iterate through the stock data, simulate trades, and update the Q-table based on the reward of each action.
- The reward function is key to the Q-Learner's success. In this case, a simple difference in price is used, but more complex rewards (e.g., considering transaction costs, risk) could be implemented.
- The loop allows the Q-Learner to experience different market conditions, reinforcing good decisions (e.g., buying low, selling high).
# Example of training loop
for epoch in range(100): # Number of epochs
state = get_initial_state(stock_data)
while not done:
action = learner.choose_action(state)
next_state, reward, done = take_action(state, action, stock_data)
learner.update_Q(state, action, reward, next_state)
state = next_state- Testing
After training, it's important to evaluate the strategy to see how well it performs in historical scenarios. Backtesting simulates how the strategy would have behaved in the past.
We can run the trained Q-Learner on the historical data and compare the performance to benchmarks like buy-and-hold.
- The Q-Learner's actions directly influence the portfolio's value. This method allows you to see if the strategy would have made money or not.
- Tracking the portfolio value (port_vals) over time gives insight into the strategy's effectiveness.
# Test the trained Q-Learner
test_state = get_initial_state(test_stock_data)
while not done:
action = learner.choose_action(test_state)
test_state, reward, done = take_action(test_state, action, test_stock_data)- Evaluation
To enhance your understanding, here's a graph showing the performance of our Q-Learning strategy compared to a simple buy-and-hold strategy.
import matplotlib.pyplot as plt
# Plot the results
plt.plot(stock_data['date'], stock_data['normalized_close'], label='Stock Price')
plt.plot(stock_data['date'], q_learning_strategy, label='Q-Learning Strategy')
plt.plot(stock_data['date'], buy_and_hold_strategy, label='Buy and Hold Strategy')
plt.legend()
plt.title('Stock Trading Strategy Performance')
plt.xlabel('Date')
plt.ylabel('Normalized Price')
plt.show()
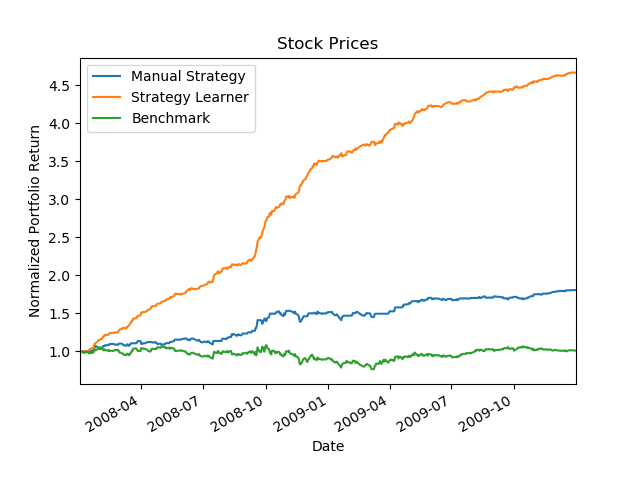
Conclusion
Creating a machine learning stock trading bot for trading covered calls involves several steps, from data collection and preprocessing to model training and trade execution. By using tools like Scikit-learn and the Alpaca API, you can automate the process and potentially generate income through a well-implemented covered call strategy.
I hope this guide helps you understand the process and inspires you to create your own trading strategies. Happy trading!